Predicción de catástrofes en Fraser River
Motivación
Se tiene información sobre el nivel medio mensual del río Fraser, en Canadá, desde Marzo de 1913 hasta Diciembre de 1990. Se pide estimar la probabilidad de que el río desborde superando los 10000 \(m^3/s\).
Datos
Los datos utilizados están disponibles en http://lib.stat.cmu.edu/datasets/fraser-river. Se tienen \(946\) observaciones de una variable (nivel medio mensual).
river <- read.table('fraser-river.txt'); head(river)## V1
## 1 485
## 2 1150
## 3 4990
## 4 6130
## 5 4780
## 6 3960Modelo
En este trabajo se considerará que las observaciones provienen de un modelo PAR (Periodic AutoRegresive), como sugiere McLeod (1994).
La periodicidad de la serie puede observarse en la siguiente figura. Note que, naturalmente, el período de la serie es 12.
ts.plot(river[1:100,], ylab='Nivel del río', xlab='Meses')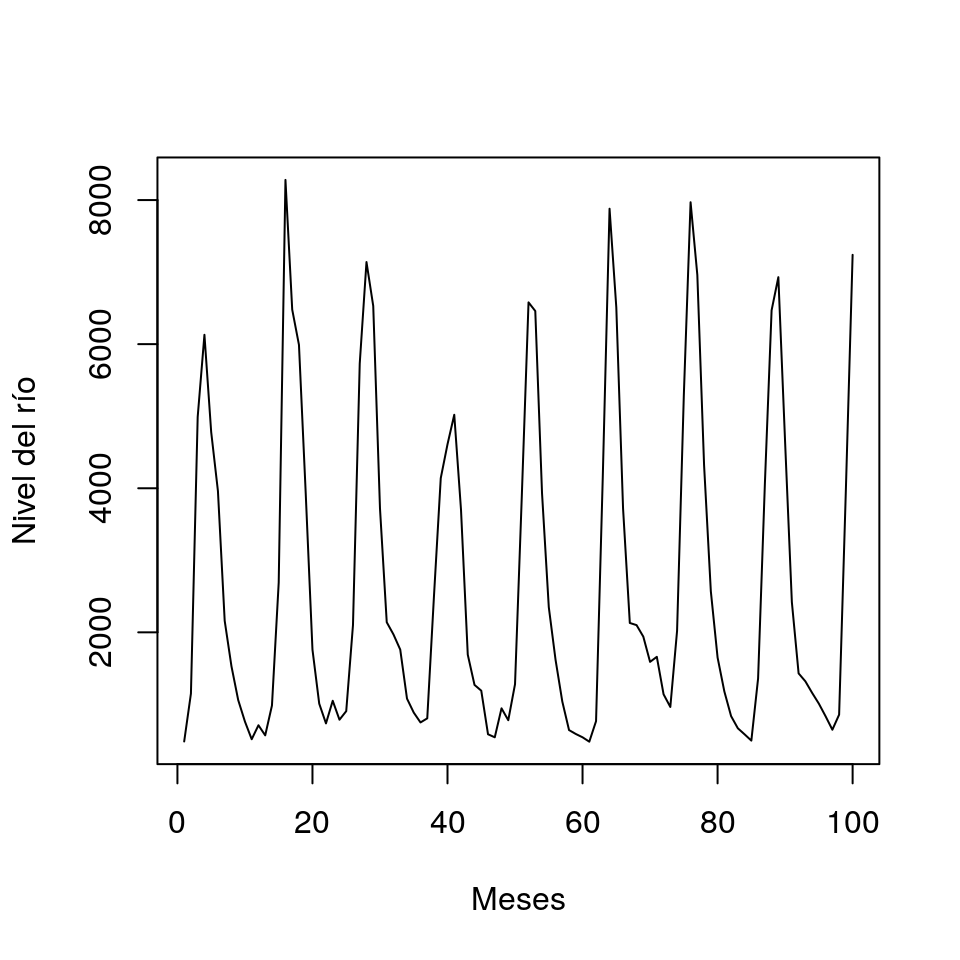
Es posible considerar también una tendencia a lo largo de los años, pero en este caso no parece haber tal relación.
En este caso, un gráfico ACF es muy informativo, pues permite estimar el orden de la dependencia entre los meses consecutivos.
acf(river)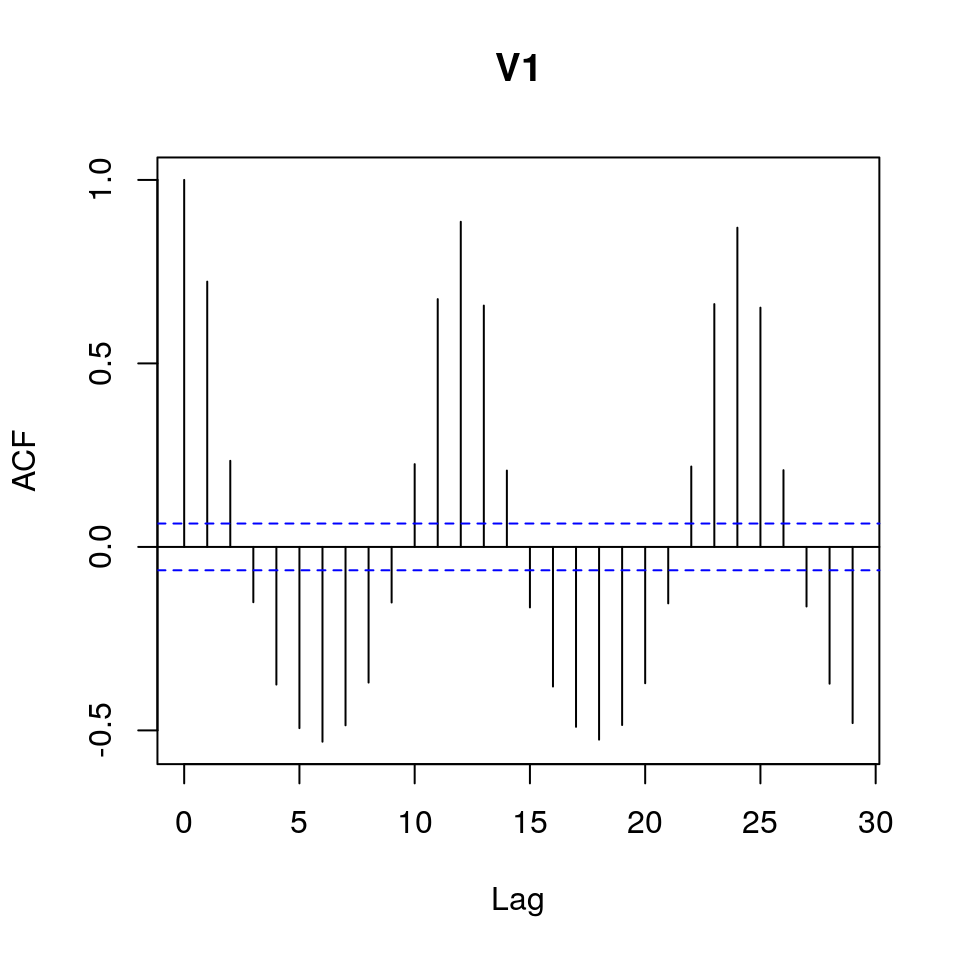
Todas las correlaciones entre meses son significativas. Aunque pudiese tratarse el problema analizando todas estas dependencias para cada mes, el modelo resultante sería demasiado complicado y posiblemente asociado a pobres estimaciones de los parámetros. Es lógico suponer que dada una fecha, el nivel del río ese mes dependerá de dos componentes: el nivel del río observado en el mes anterior y el nivel medio histórico del río ese mes. Se formulará este problema como sigue,
\[ y_t = \phi_{0s} + \phi_{1s} y_{t-1} + \varphi_{s}\epsilon_t, \quad \epsilon_t \sim N(0,1), \] donde \(s=1,2 \ldots 12\), \(t=1,2 \ldots n\).
Esta formulación corresponde a un modelo PAR(1) - Periodic Autoregressive model of first order. Es muy similar a la de un modelo AR(1), cuya implementación en stan puede encontrarse en el manual oficial de stan. Un modelo AR(1) tiene la forma, \[ y_t = \phi_{0} + \phi_{1} y_{t-1} + \varphi \epsilon_t, \quad \epsilon_t \sim N(0,1).\]
El modelo PAR(1) puede interpretarse como una extensión natural del AR(1) para trabajar con datos periódicos.
Los parámetros \(\phi_{0s}\) controlan el nivel medio del río en cada mes según el hitórico, mientras que \(\phi_{1s}\) determina la tendencia para cada mes. Es lógico suponer que la varianza \(\varphi_s\) varía según el mes. Por ejemplo, el mes de Marzo suele ser poco lluvioso siempre, mientras que otros meses como Mayo pueden ser lluviosos o no.
El modelo jerárquico queda,
- \(Y_{t} \big|\{ \phi_{0s}, \phi_{1s}, \varphi_s, Y_{t-1} \} \sim Normal(\phi_{0s} + \phi_{1s} Y_{t-1}, \varphi_s)\),
- \(\phi_{0s}\sim Normal(\mu_0, \sigma_0^2)\),
- \(\phi_{1s}\sim Normal(\mu_1, \sigma_1^2)\),
- \(\varphi_{s}^2\sim InvGamma(\alpha, \beta)\).
Note que \(s\) depende de \(t\). Por ejemplo, \(t= 12n+s\), \(n\in \mathbb{Z}_+\).
Para responder la cuestión inicial estamos interesados en estudiar la distribución marginal del vector aleatorio \((Y_1, Y_2, Y_3 \ldots )\).
Implementación
Para estimar los parámetros del modelo se ha utilizado la librería rstan de R.
Se ha aplicado previamente a los datos una transformación logarítmica. Esto lo sugiere McLeod (1994), cuando se tienen datos reales, con el fin de estabilizar la varianza.
# Centramos los datos para que las observaciones comiencen en el mes de enero.
flow <- log(c(as(river[-(1:10),],'double'),as(river[(1:10),],'double')))
library(refund)
library(refund.shiny)
library(tidyverse)
river.flow <- matrix(flow[1:936], ncol= 12, byrow = T)
as_refundObj(river.flow) %>%
ggplot(aes(x = index, y = value, group = id)) + geom_path(alpha = .2)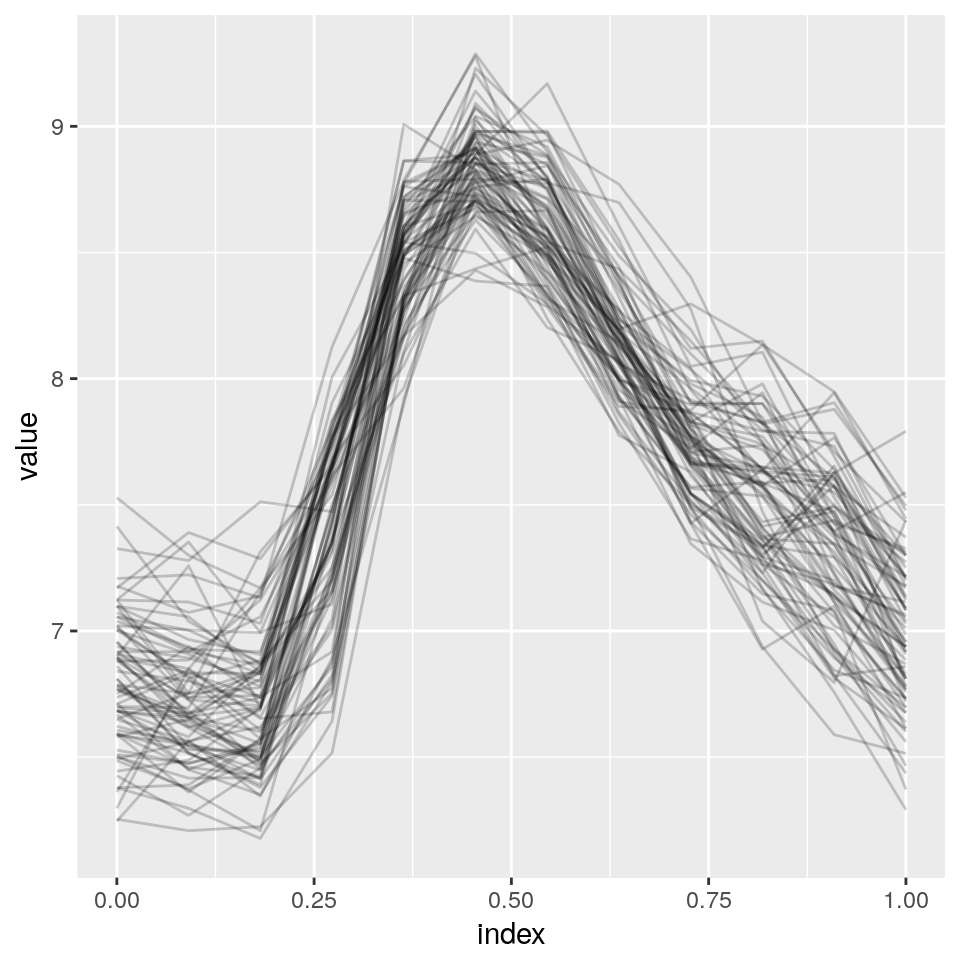
Para estimar la probabilidad de que el río desborde simularemos muchas observaciones de la serie. La probabilidad de que el río desborde será estimada a través de la proporción de veces que el nivel medio ha sobrepasado el límite en las series simuladas. Note que, como señala Hoff (2009), con los algoritmos de Monte Carlo y MCMC no se genera más información que aquella presente en los datos y en la prior.
El código del programa en Stan para el modelo considerado sería como sigue.
programa<-'
data{
// Datos externos
int<lower=1> N; // Tamaño de la serie
int<lower=1> N_new; // Tamaño de la serie a predecir
real y[N]; // Serie observada
real jan_new; // Valor (fijo) del mes de Enero de la serie a predecir
real mu0;
real<lower=0> sigma0;
real mu1;
real<lower=0> sigma1;
real<lower=0> alpha;
real<lower=0> beta;
}
parameters{
// Parámetros a estimar
real phi0[12]; // Nivel histórico medio mensual
real phi1[12]; // Pendiente cada mes y el siguiente
real<lower=0> varphi2[12]; // Varianza del nivel medio por mes
}
transformed parameters{
// Transformaciones para notación
real<lower=0> varphi[12];
for(s in 1:12){
varphi[s]=sqrt(varphi2[s]);
}
}
model{
// Formulación del modelo
int season;
season = 2;
for(i in 2:N){
y[i] ~ normal( phi0[season]+phi1[season]*y[i-1], varphi[season] );
season=season+1;
if(season>12){
season=1;
}
}
for (s in 1:12){
phi0[s] ~ normal( mu0, sigma0 ); // densidad a-priori normal
phi1[s] ~ normal( mu1, sigma1 );
varphi2[s] ~ inv_gamma( alpha, beta ); // densidad a-priori inversa gamma
}
}
generated quantities{
// Valores simulados para estimar
vector[N_new] y_new;
int season;
season = 2;
y_new[1]=jan_new;
for(i in 2:N_new){
y_new[i] = normal_rng( phi0[season]+phi1[season]*y_new[i-1], varphi[season] );
season=season+1;
if(season>12){
season=1;
}
}
}
'Compilamos el código de Stan.
library(rstan)
rstan_options(auto_write=T)
options(mc.cores=parallel::detectCores()-1)
programa_c<-stan_model(model_code=programa)Preparamos los parámetros del modelo.
N <- length(flow)
N_new <- 144
jan_new <- flow[1]
alpha <- 0.5 -> beta
mu0 <- 3
sigma0 <- 100
mu1 <- 0
sigma1 <- 100
datos <- list(y=flow, N=N, N_new=N_new, jan_new=jan_new, mu0=mu0, sigma0=sigma0, mu1=mu1, sigma1=sigma1, beta=beta, alpha=alpha)Note que se ha considerado una a priori poco informativa para la media mensual del nivel del río y la pendiente entre meses consecutivos, pues se tiene una muestra de datos suficientemente grande para estimar estos parámetros. Para la varianza del nivel medio mensual también se ha considerado una a-priori poco informativa, equivalente a una observación con varianza \(1\).
Simulamos del modelo de Stan.
result <- sampling(programa_c, data=datos, iter=1500, chains=1) ##
## SAMPLING FOR MODEL '842b86bbb4ad5f287b88b8bb7fe0b935' NOW (CHAIN 1).
##
## Chain 1, Iteration: 1 / 1500 [ 0%] (Warmup)
## Chain 1, Iteration: 150 / 1500 [ 10%] (Warmup)
## Chain 1, Iteration: 300 / 1500 [ 20%] (Warmup)
## Chain 1, Iteration: 450 / 1500 [ 30%] (Warmup)
## Chain 1, Iteration: 600 / 1500 [ 40%] (Warmup)
## Chain 1, Iteration: 750 / 1500 [ 50%] (Warmup)
## Chain 1, Iteration: 751 / 1500 [ 50%] (Sampling)
## Chain 1, Iteration: 900 / 1500 [ 60%] (Sampling)
## Chain 1, Iteration: 1050 / 1500 [ 70%] (Sampling)
## Chain 1, Iteration: 1200 / 1500 [ 80%] (Sampling)
## Chain 1, Iteration: 1350 / 1500 [ 90%] (Sampling)
## Chain 1, Iteration: 1500 / 1500 [100%] (Sampling)
## Elapsed Time: 54.941 seconds (Warm-up)
## 51.5356 seconds (Sampling)
## 106.477 seconds (Total)Extraemos los resultados del modelo.
result.sim <- rstan::extract(result)
# Número medio de desbordamientos en la simulación.
mean(result.sim$y_new[,]>log(10000)) ## [1] 0.005277778# Número medio de desbordamientos en la simulación para el mes de Junio.
mean(result.sim$y_new[,12*(2:11)+6]>log(10000)) ## [1] 0.04666667Podemos observar las trayectorias simuladas.
river.flow <- matrix(t(result.sim$y_new[sample(1:500, 30),13:144]), ncol= 12, byrow = T)
as_refundObj(river.flow) %>%
ggplot(aes(x = index, y = value, group = id)) + geom_path(alpha = .1)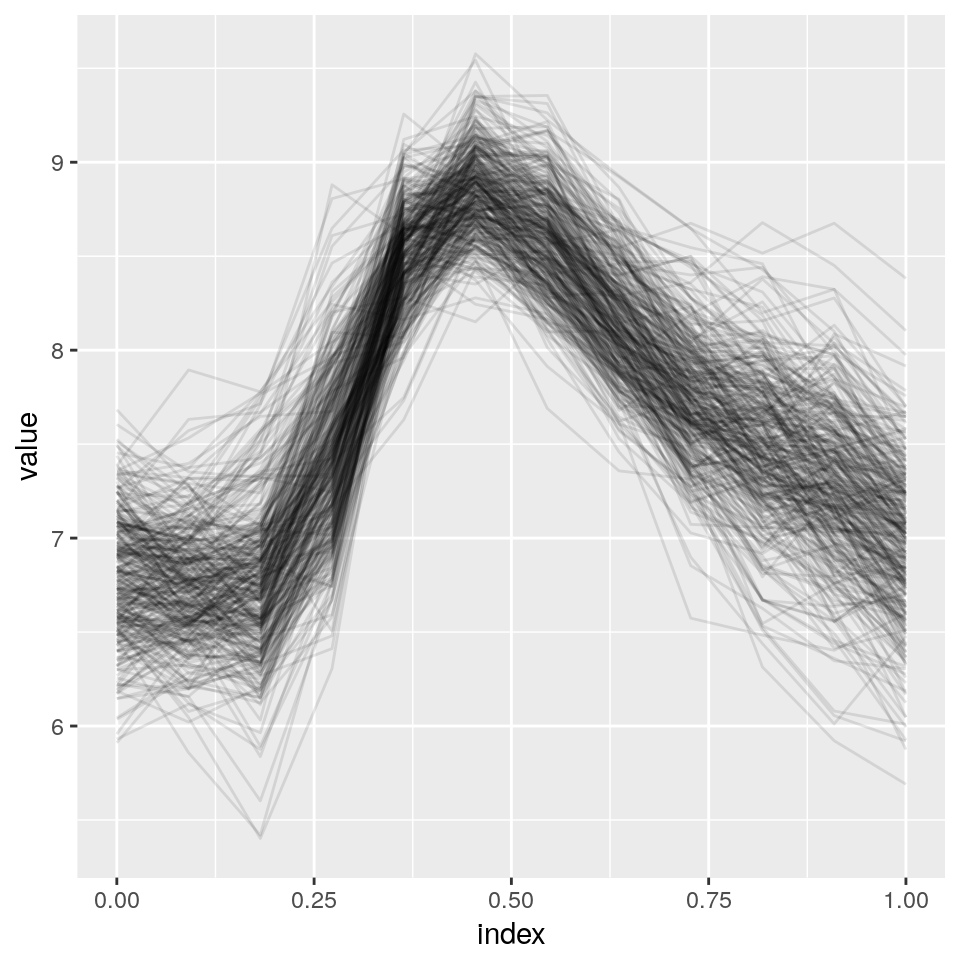
Podemos visualizar la función de densidad marginal del nivel medio del río en cierto mes.
river.flow <- matrix(t(result.sim$y_new[,13:144]), ncol= 12, byrow = T)
dat <- data.frame(river.flow)
names(dat)<-month.name
plot.datos<-data.frame(Month=rep(c('Abril','Mayo'), each=nrow(dat)), River=c(dat$April, dat$May))
ggplot(plot.datos, aes(x=River, fill=Month, colour=Month))+geom_density(alpha=0.3)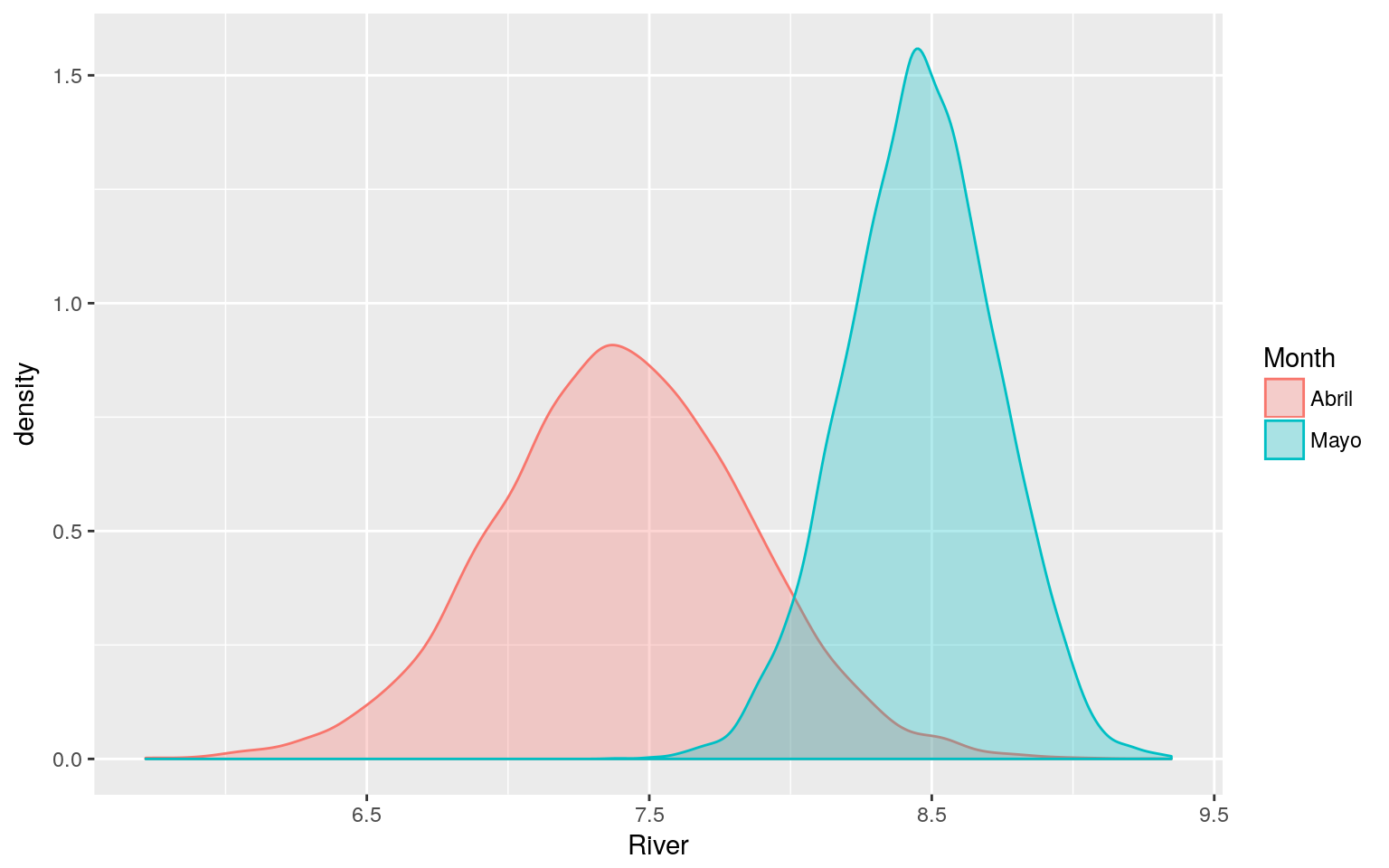
Como se observa en la figura anterior, el modelo estimado capta la diferencia en el régimen de lluvias entre los meses de Abril y Mayo.
Diagnósticos
Diagnóstico usando el traceplot del muestreo de Gibbs para la variable \(\phi_{01}\).
traceplot(result, pars="phi0[1]", inc_warmup=TRUE)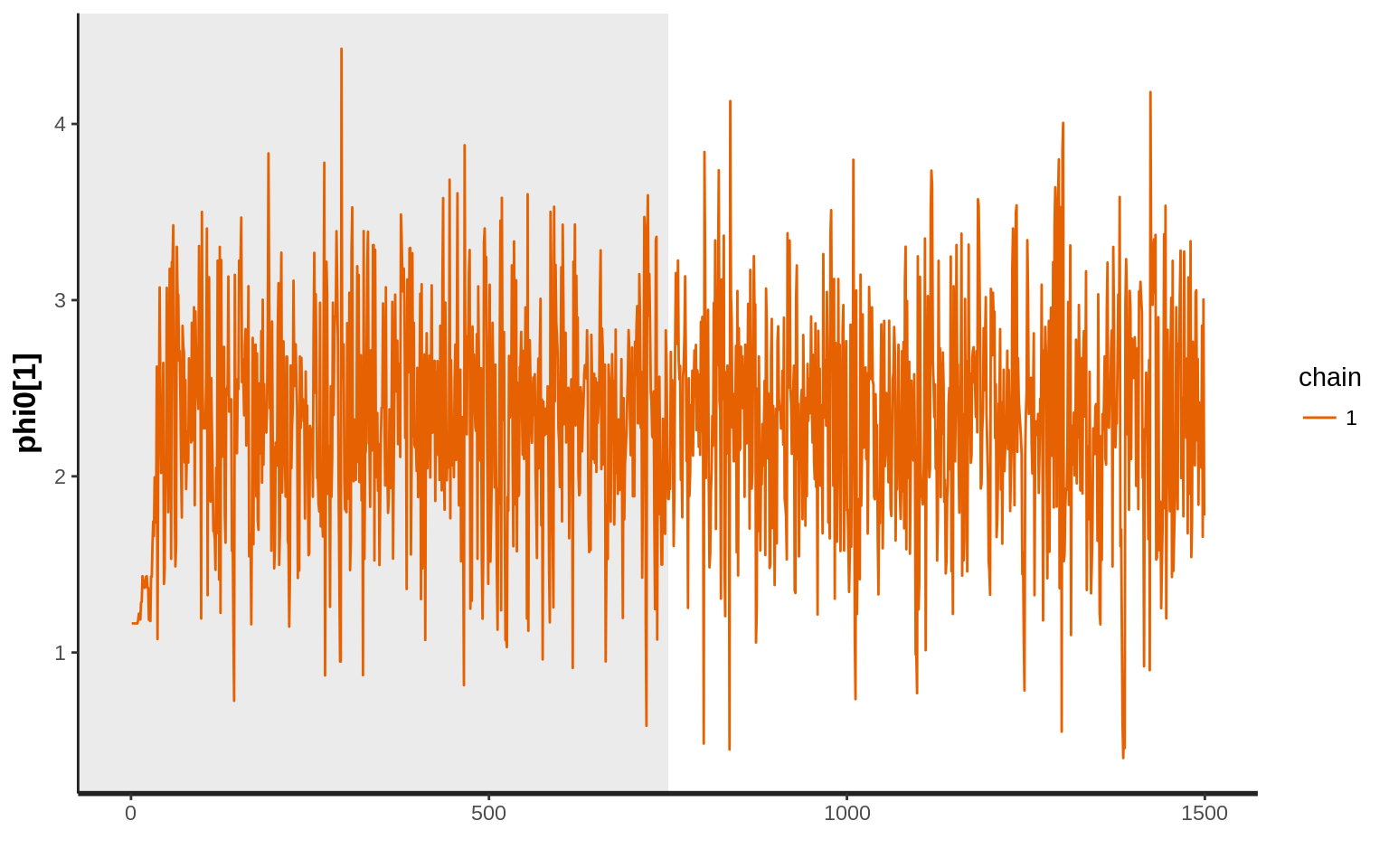
También es posible diagnosticar la simulación observando las columnas Rhat y n_eff (número efectivo de observaciones simuladas).
print(result, pars = result@sim$pars_oi[c(1,2,4)])## Inference for Stan model: 842b86bbb4ad5f287b88b8bb7fe0b935.
## 1 chains, each with iter=1500; warmup=750; thin=1;
## post-warmup draws per chain=750, total post-warmup draws=750.
##
## mean se_mean sd 2.5% 25% 50% 75% 97.5% n_eff Rhat
## phi0[1] 2.32 0.03 0.61 1.14 1.94 2.33 2.72 3.50 507 1
## phi0[2] 2.12 0.02 0.62 0.89 1.71 2.13 2.52 3.38 728 1
## phi0[3] 0.59 0.04 0.79 -0.87 0.04 0.58 1.13 2.25 488 1
## phi0[4] 2.30 0.03 0.71 0.86 1.88 2.28 2.78 3.68 530 1
## phi0[5] 7.17 0.02 0.54 6.04 6.80 7.18 7.54 8.23 507 1
## phi0[6] 7.25 0.04 0.94 5.40 6.64 7.24 7.87 9.15 547 1
## phi0[7] 1.39 0.04 1.09 -0.76 0.68 1.42 2.12 3.48 611 1
## phi0[8] 1.40 0.03 0.70 0.05 0.93 1.41 1.86 2.82 572 1
## phi0[9] 1.29 0.03 0.81 -0.26 0.76 1.26 1.81 2.82 591 1
## phi0[10] 0.43 0.04 0.86 -1.26 -0.13 0.40 1.01 2.19 508 1
## phi0[11] 1.69 0.04 0.86 0.07 1.11 1.69 2.24 3.43 473 1
## phi0[12] 1.53 0.03 0.62 0.35 1.17 1.51 1.92 2.80 562 1
## phi1[1] 0.64 0.00 0.09 0.47 0.58 0.64 0.70 0.81 509 1
## phi1[2] 0.68 0.00 0.09 0.49 0.62 0.68 0.74 0.86 726 1
## phi1[3] 0.91 0.01 0.12 0.66 0.83 0.91 0.99 1.13 482 1
## phi1[4] 0.76 0.00 0.11 0.55 0.69 0.76 0.82 0.97 537 1
## phi1[5] 0.17 0.00 0.07 0.03 0.13 0.17 0.22 0.33 511 1
## phi1[6] 0.19 0.00 0.11 -0.04 0.11 0.19 0.26 0.41 545 1
## phi1[7] 0.82 0.00 0.12 0.58 0.73 0.81 0.89 1.06 610 1
## phi1[8] 0.79 0.00 0.08 0.62 0.73 0.78 0.84 0.94 571 1
## phi1[9] 0.79 0.00 0.10 0.61 0.73 0.80 0.86 0.98 591 1
## phi1[10] 0.92 0.00 0.11 0.68 0.84 0.92 0.99 1.13 506 1
## phi1[11] 0.75 0.01 0.11 0.52 0.68 0.75 0.82 0.96 476 1
## phi1[12] 0.74 0.00 0.08 0.57 0.69 0.75 0.80 0.91 563 1
## varphi[1] 0.22 0.00 0.02 0.19 0.21 0.22 0.23 0.26 750 1
## varphi[2] 0.22 0.00 0.02 0.19 0.20 0.21 0.23 0.25 750 1
## varphi[3] 0.27 0.00 0.02 0.23 0.25 0.27 0.28 0.31 750 1
## varphi[4] 0.32 0.00 0.03 0.28 0.30 0.32 0.34 0.38 750 1
## varphi[5] 0.25 0.00 0.02 0.22 0.24 0.25 0.26 0.29 750 1
## varphi[6] 0.22 0.00 0.02 0.19 0.20 0.22 0.23 0.25 750 1
## varphi[7] 0.21 0.00 0.02 0.18 0.20 0.21 0.22 0.25 750 1
## varphi[8] 0.17 0.00 0.01 0.15 0.16 0.17 0.18 0.20 750 1
## varphi[9] 0.20 0.00 0.02 0.17 0.19 0.20 0.21 0.23 750 1
## varphi[10] 0.24 0.00 0.02 0.20 0.22 0.23 0.25 0.28 750 1
## varphi[11] 0.26 0.00 0.02 0.22 0.24 0.26 0.27 0.30 750 1
## varphi[12] 0.23 0.00 0.02 0.20 0.22 0.23 0.24 0.27 750 1
##
## Samples were drawn using NUTS(diag_e) at Sat Apr 29 12:27:33 2017.
## For each parameter, n_eff is a crude measure of effective sample size,
## and Rhat is the potential scale reduction factor on split chains (at
## convergence, Rhat=1).En este caso, Rhat es muy cercano a \(1\) y n_eff es suficientemente grande.
Resultados
Respondiendo la motivación inicial, la probabildad estimada de que el río desborde superando los 10000 \(m^3/s\) en un mes es cercana a \(5\cdot 10^{-3}\). No obstante, usando el enfoque considerado se puede ser más específico en la respuesta. Por ejemplo, la probabilidad de que el río desborde en el mes de Junio es de aproximadamente \(5 \cdot 10^{-2}\).
Hoff, P.D. 2009. A First Course in Bayesian Statistical Methods. Springer Texts in Statistics. Springer New York. https://books.google.es/books?id=V8jT2SimGR0C.
McLeod, A Ian. 1994. “Diagnostic Checking of Periodic Autoregression Models with Application.” Journal of Time Series Analysis 15 (2). Wiley Online Library: 221–33.